Preference Graphs
pip install prefgraph # core library
pip install "prefgraph[parquet]" # + Parquet file support
pip install "prefgraph[datasets]" # + real-world dataset loaders
See the Installation page for all extras and workflow options.
When users make choices, we can represent their decisions as a preference graph. If someone chooses A over B, B over C, and then C over A, they have formed a cycle. These cycles could represent an inconsistency in their decision making. PrefGraph uses graph algorithms (like Tarjan's SCC) to detect these cycles. By identifying and counting these violations, we can score a user's consistency.
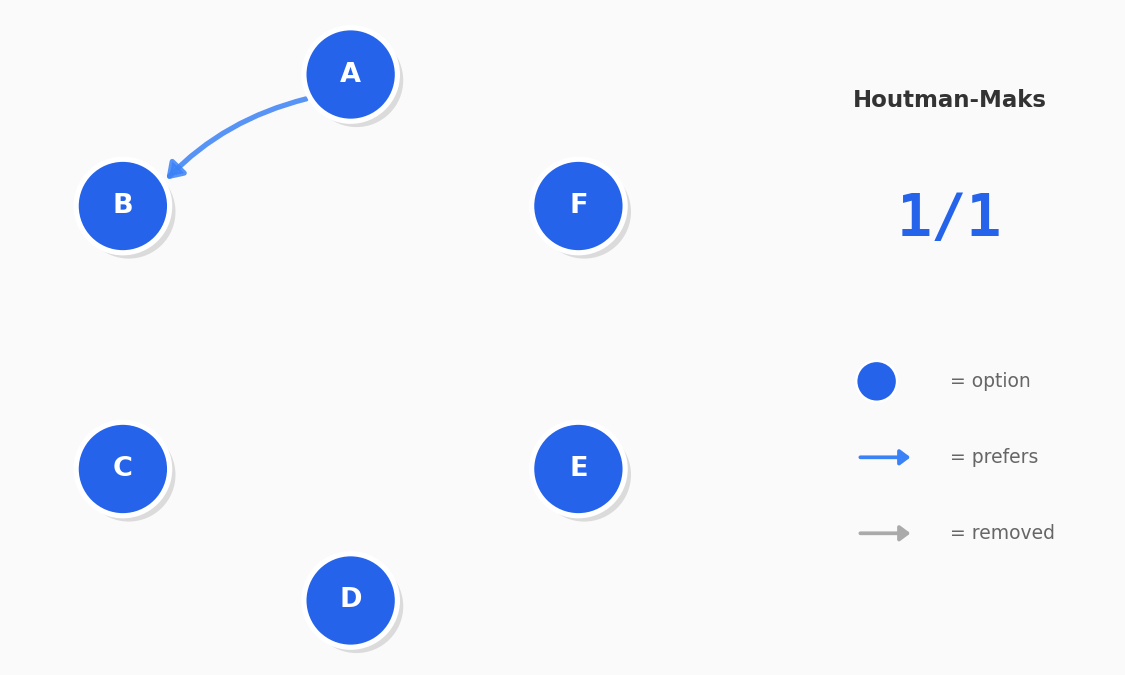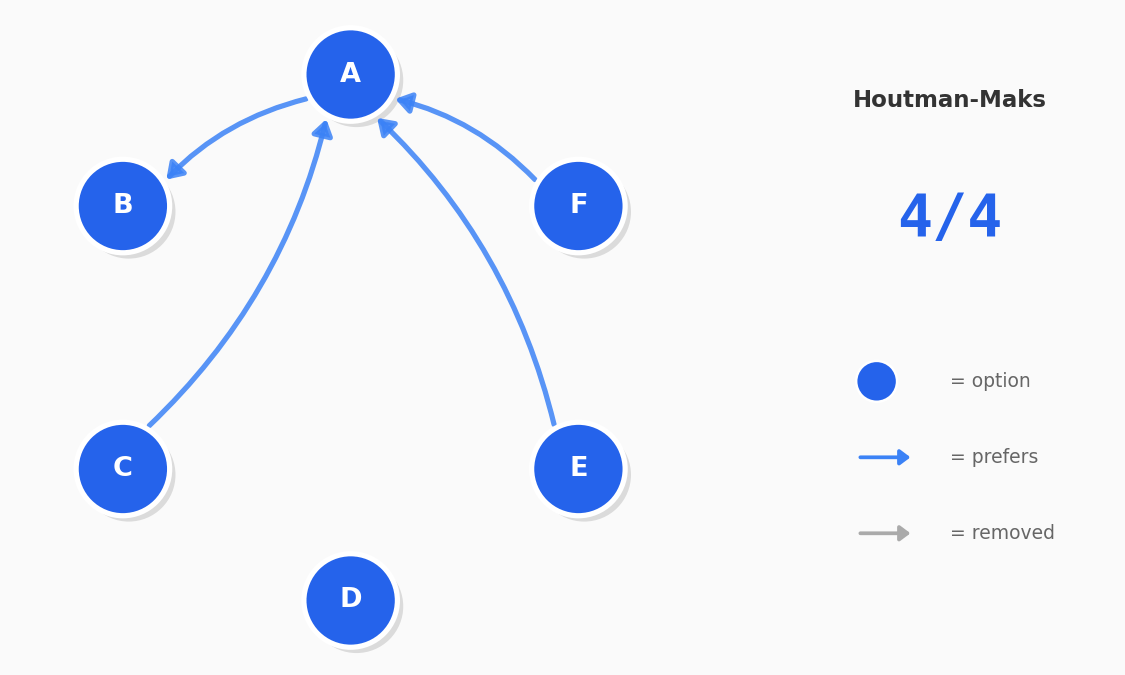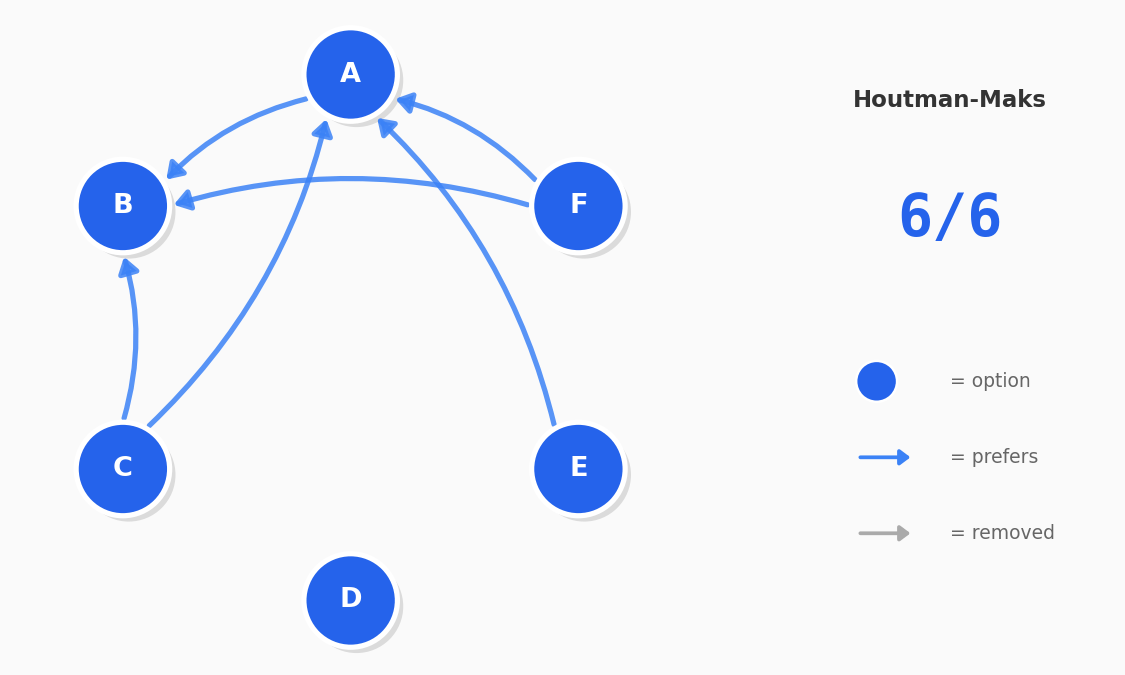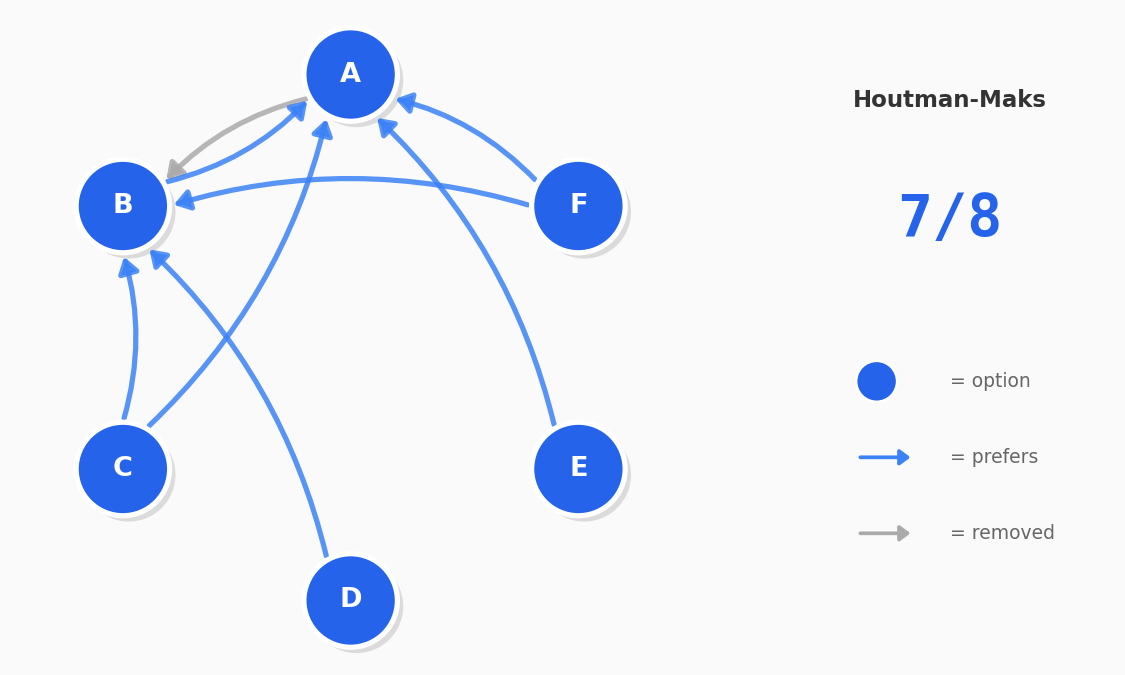
Before You Trust the Scores
Consistency scores are only meaningful when the input data represents genuine feasible choices. Menus must reflect what the user actually saw, not a retroactive reconstruction from purchase logs. Keep only clean single-choice sessions where the user picked exactly one item. The chosen item must be present in the menu. Item IDs must be remapped to contiguous 0..N-1 indices before scoring. For budget data, prices must be positive and quantities non-negative. The Engine now rejects NaN, Inf, negative prices, out-of-range item IDs, and duplicate menu items with clear error messages, but the harder question is whether your menus and budgets approximate real choice sets at all. If they do not, the scores measure data artifacts, not behavior. See the Loading Data guide for worked examples of building clean inputs from raw event logs.
Examples
Inconsistency in AI Agents
Do LLMs have stable action rankings, or does the ranking change when different alternatives are shown? We queried GPT-4o-mini across 5 enterprise scenarios (support triage, alert routing, content moderation, hiring, procurement), each with 10 vignettes, 5 prompt frameworks, and 15 menus per vignette. The deterministic stage collected 3,750 calls at temperature 0; the stochastic stage sampled each menu 20 times at temperature 0.7, adding 75,000 calls — roughly 78,750 API calls in total over 15 hours. We built preference graphs from these responses and tested for logical cycles. All vignettes are synthetic and results come from a single model family, so these numbers are a diagnostic demo rather than a general benchmark. Full results: Detecting Inconsistency in AI Agents.
Operational Scenario |
Perfect Consistency (%) |
Probabilistic Consistency (%) |
|---|---|---|
Support |
88 |
54 |
Alert |
92 |
74 |
Content Moderation Task |
82 |
60 |
Jobs Task |
74 |
62 |
Procurement |
84 |
61 |
Predicting Customer Spend and Engagement
We tested whether revealed preference features improve user-level predictions across 11 datasets and 32 targets. Under 5-fold cross-validation, the median lift is zero. The one exception is Amazon churn prediction. Despite near-zero predictive lift, three revealed preference features rank in the top ten by model importance. Full results: Predicting Customer Spend and Engagement.
Dataset |
N |
Target |
Base AUC-PR |
+RP AUC-PR |
|---|---|---|---|---|
Amazon |
4,694 |
Spend Drop |
.226 |
.248 |
REES46 |
8,832 |
Low Loyalty |
.709 |
.715 |
H&M |
46,757 |
High Spender |
.683 |
.682 |
FINN |
46,858 |
Low Loyalty |
.780 |
.781 |
Performance
The Rust engine processes users in parallel via Rayon and streams them in fixed-size chunks, so memory stays flat regardless of population size. On a 10-core laptop, scoring 100,000 users across five metrics from a 110 MB Parquet file takes under two minutes. See the Performance Benchmarks page for details.
Metrics |
Throughput (users/sec) |
Latency (per user) |
|---|---|---|
GARP Only (O(T²)) |
~49,000 |
20 μs |
GARP + CCEI |
~2,400 |
420 μs |
Comprehensive (GARP, CCEI, MPI, HARP) |
~2,000 |
500 μs |
Configuration |
10K users |
100K users |
1M users |
|---|---|---|---|
GARP (O(T²)) |
0.1s |
2.0s |
~20s |
GARP + CCEI |
4.2s |
39.5s |
~6.6 min |
Comprehensive Suite |
6.8s |
67.1s |
~11 min |
Configuration |
10K users |
100K users |
1M users |
|---|---|---|---|
SARP + WARP + HM |
0.3s |
5.2s |
85.6s |
Explore the API Reference and References for more.