Performance Benchmarks
PrefGraph uses a Rust engine (rpt-core) for batch choice analysis. It combines Rayon parallelism with graph algorithms and HiGHS linear programming, streaming users in chunks to keep memory bounded.
Scalability and Throughput
Throughput scales roughly linearly with core count since each user is independent. On a 10-12 core CPU, GARP-only processing reaches about 49k users/sec. Adding CCEI yields about 2.4k/sec. The full suite (GARP, CCEI, MPI, HARP) sustains about 2.0k/sec.
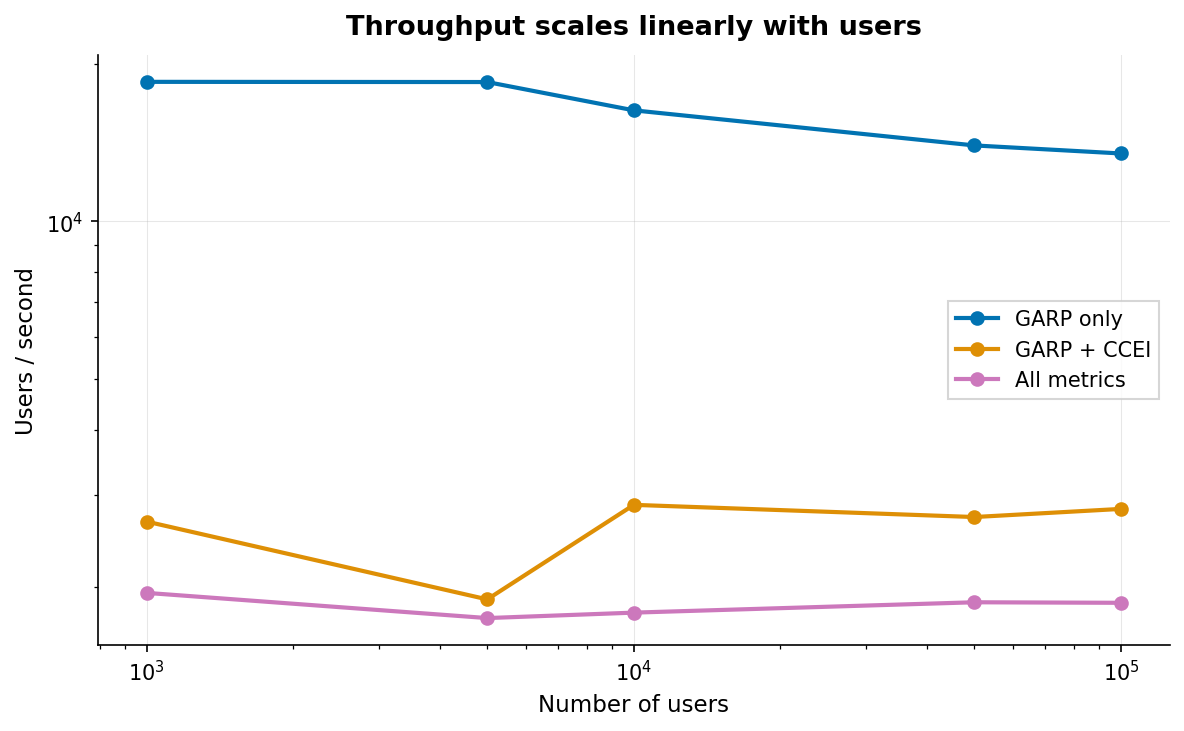
Per-user latency is about 20 microseconds for GARP-only, 420 microseconds for GARP+CCEI, and 500 microseconds for the full four-metric suite. These figures vary with core count and clock speed.
Metrics |
Throughput (users/sec) |
Latency (per user) |
|---|---|---|
GARP Only (O(T²)) |
~49,000 |
20 μs |
GARP + CCEI |
~2,400 |
420 μs |
Comprehensive (GARP, CCEI, MPI, HARP) |
~2,000 |
500 μs |
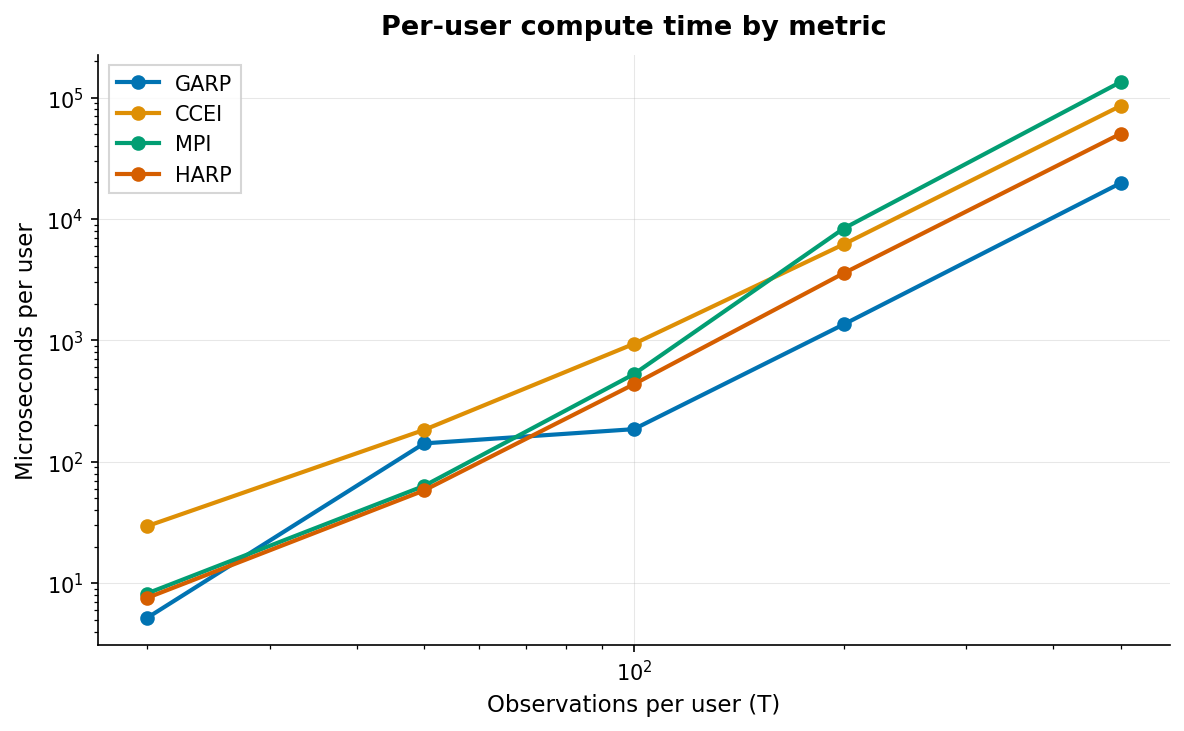
Computational Complexity by Metric
Throughput varies by algorithm complexity. See Algorithms for details.
Memory Management and Streaming
The engine maintains a flat memory profile by streaming users in fixed-size chunks. By default, batches of 50k users are processed, and intermediate buffers are released between batches, so peak memory depends on chunk size rather than total population.
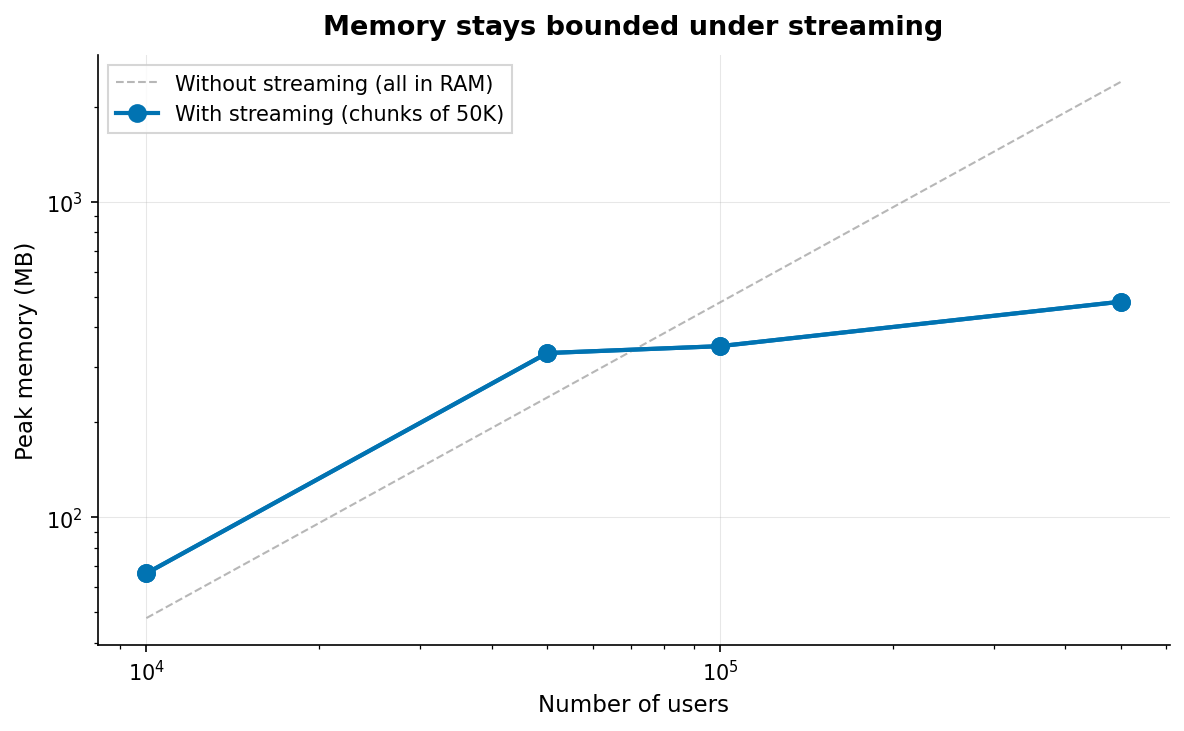
At the default chunk size, peak memory is 100-200 MB. Million-user runs work on a laptop. Adjust chunk size to trade memory for throughput.
Large-Scale Benchmarks
For budgets with T=20–100 and K=5, GARP alone completes 10k, 100k, and 1M users in roughly 0.1s, 2.0s, and ~20s. Adding CCEI yields about 4.2s, 39.5s, and ~6.6 minutes. Running the full suite (GARP, CCEI, MPI, HARP) takes around 6.8s, 67.1s, and ~11 minutes for the same scales.
On discrete menus (50 items, 20–100 sessions), the SARP+WARP+HM bundle completes ~0.3s at 10k users, ~5.2s at 100k, and ~85.6s at 1M. Measured on Apple M-series hardware. Timings scale with core count.
Configuration |
10K users |
100K users |
1M users |
|---|---|---|---|
GARP (O(T²)) |
0.1s |
2.0s |
~20s |
GARP + CCEI |
4.2s |
39.5s |
~6.6 min |
Comprehensive Suite |
6.8s |
67.1s |
~11 min |
Configuration |
10K users |
100K users |
1M users |
|---|---|---|---|
SARP + WARP + HM |
0.3s |
5.2s |
85.6s |
End-to-End from Disk
The benchmarks above measure in-memory scoring. Below is the full disk-to-scores pipeline on 100,000 synthetic consumers (T=15, K=5, full 5-metric suite).
Pipeline |
Read |
Transform |
Score |
Total |
File Size |
|---|---|---|---|---|---|
CSV + Polars |
63 ms |
18.0 s |
1m 32s |
1m 50s |
281 MB |
Parquet + Polars |
68 ms |
14.1 s |
1m 43s |
1m 57s |
110 MB |
Parquet (streaming) |
— |
— |
— |
1m 45s |
110 MB |
Pipeline |
Total |
|---|---|
In-memory |
131 ms |
CSV + reconstruct |
200 ms |
File I/O adds under 70 ms for 280 MB. The Rust scoring step dominates wall time for anything beyond GARP-only. Parquet streaming via engine.analyze_parquet() skips the Python transformation step and reaches about 950 users/sec for the full suite. Parquet with zstd is 2.6x smaller than CSV.
Complexity Summary
GARP runs in O(T²), CCEI in O(T² log T), MPI and HARP in O(T³). Houtman-Maks uses greedy FVS with exact ILP for small T. Utility recovery and VEI each solve LPs at O(T²) scale.
Algorithm |
Complexity |
Implementation Notes |
|---|---|---|
GARP |
O(T²) |
SCC-based arc-scan; avoids O(T³) transitive closure. |
CCEI (AEI) |
O(T² log T) |
Iterative binary search over T² potential efficiency ratios. |
MPI |
O(T³) |
Karp’s maximum-mean-weight cycle algorithm. |
HARP |
O(T³) |
Max-product path calculation via modified Floyd-Warshall. |
Houtman-Maks |
O(T²) / ILP |
Greedy FVS (approximate); ILP via HiGHS for exact solutions (T ≤ 200). |
Utility Recovery |
O(T²) |
Linear programming with 2T variables and T(T-1) constraints. |
VEI |
O(T²) |
Observation-specific efficiency via constrained optimization. |
Hardware Configuration
All results are from an Apple M-series machine (11 cores). On a 64-core server, throughput is roughly 5x higher.