LLM Prompt Consistency
A controlled experiment testing whether different system prompts cause LLMs to make inconsistent choices when selecting from package menus.
Introduction
When deploying LLM agents for decision-making (tool selection, package choice, resource allocation), a natural requirement is consistency: the agent should have a stable preference ranking that doesn’t depend on which alternatives happen to be shown. If a system prompt causes the agent to prefer package A over B in one context but B over A in another, no fixed ranking can explain the choices — the prompt induces decision incoherence.
Chen et al. (2023, PNAS) tested GPT on budget-allocation tasks and found high CCEI (0.95–0.999). But their setup used continuous budget lines, not discrete menus. We test discrete menu choice — closer to how LLMs are actually deployed (selecting tools, APIs, packages from a shortlist) — and vary the system prompt rather than the model.
What you’ll learn:
How to design a controlled SARP experiment for LLM agents
Why system prompts can introduce cycles into the item graph
How to measure prompt-induced inconsistency with Houtman-Maks
A practical pipeline for auditing prompts before deployment
Companion script: examples/applications/02_llm_alignment.py
Formal Setup
SARP for prompt testing
Build the item graph \(G\) from all trials. SARP holds iff the transitive closure \(G^*\) is acyclic:
A SARP violation means the prompt causes the agent to have circular
preferences — it chose requests over httpx in one trial but
httpx over requests in another (with both in the menu).
Experiment Design
Task
Context: "You are working on a Python project that needs to make
HTTP requests to external APIs. Choose one package."
Packages (items):
A: requests - classic, stable, synchronous
B: httpx - modern, async-capable
C: aiohttp - async-first
D: urllib3 - low-level, foundational
E: httplib2 - legacy
System prompt treatments
The independent variable is the system prompt. Five treatments:
Prompt |
Content |
|---|---|
neutral |
“You are a helpful assistant.” |
expert |
“You are a senior Python developer with 10 years of experience building production web services.” |
cautious |
“You are a careful engineer who prioritizes stability, security, and backward compatibility.” |
innovative |
“You are a cutting-edge developer who loves modern tools and async patterns.” |
minimal |
(no system prompt) |
Trials
60 trials per prompt, 5 prompts, 2 temperatures = 600 API calls total
First 10 menus: all C(5,2)=10 pairwise comparisons (guaranteed coverage)
Remaining menus: random subsets of size 2–4
Same menu sequence across all prompts (controlled comparison)
Model: GPT-4o-mini at temperature 0.0 (baseline) and 0.7
Warning
Methodological caveat. SARP is an axiom for deterministic choice.
At temperature 0.7, GPT samples tokens stochastically, so SARP
violations may reflect sampling noise rather than genuine preference
cycles. A model with a stable 80/20 preference for requests over
httpx will produce SARP violations purely from minority draws.
For a rigorous treatment, repeat identical menus to estimate choice
probabilities, then test with stochastic choice axioms (RUM
consistency, regularity) available in prefgraph.contrib.stochastic.
Also run a temperature-0 baseline: if violations vanish at temp=0,
they are sampling artifacts, not prompt-induced inconsistency.
Algorithm
PROMPT-SARP-EXPERIMENT(prompts P, trials T):
─────────────────────────────────────────────
1. GENERATE MENUS
For t = 1, ..., T:
Mₜ ← random subset of {A,B,C,D,E}, size 2-4
2. QUERY LLM (per prompt)
For each prompt p ∈ P:
For each trial t:
response ← GPT(system=p, user=context + Mₜ)
cₜ ← parse(response) // extract package name
Build MenuChoiceLog(menus, choices)
3. SARP TEST (per prompt) O(N³) where N=5
Build item graph G on {A,B,C,D,E}
G* ← Floyd-Warshall(G)
Check for cycles in G*
4. HOUTMAN-MAKS (per prompt) O(T) approx
Find min trials to remove for SARP consistency
HM efficiency = 1 - (removed / T)
5. COMPARE PROMPTS
Rank prompts by HM efficiency
Identify which prompt induces most/least consistency
Running the Experiment
# Preview without API calls
python examples/applications/02_llm_alignment.py --dry-run
# Quick test (20 trials per prompt)
export OPENAI_API_KEY=your_key
python examples/applications/02_llm_alignment.py --trials 20
# Full experiment with temp=0 baseline (60 trials × 5 prompts × 2 temps = 600 calls, ~$0.03)
python examples/applications/02_llm_alignment.py --trials 60 --baseline
# Reanalyze cached responses
python examples/applications/02_llm_alignment.py --cached
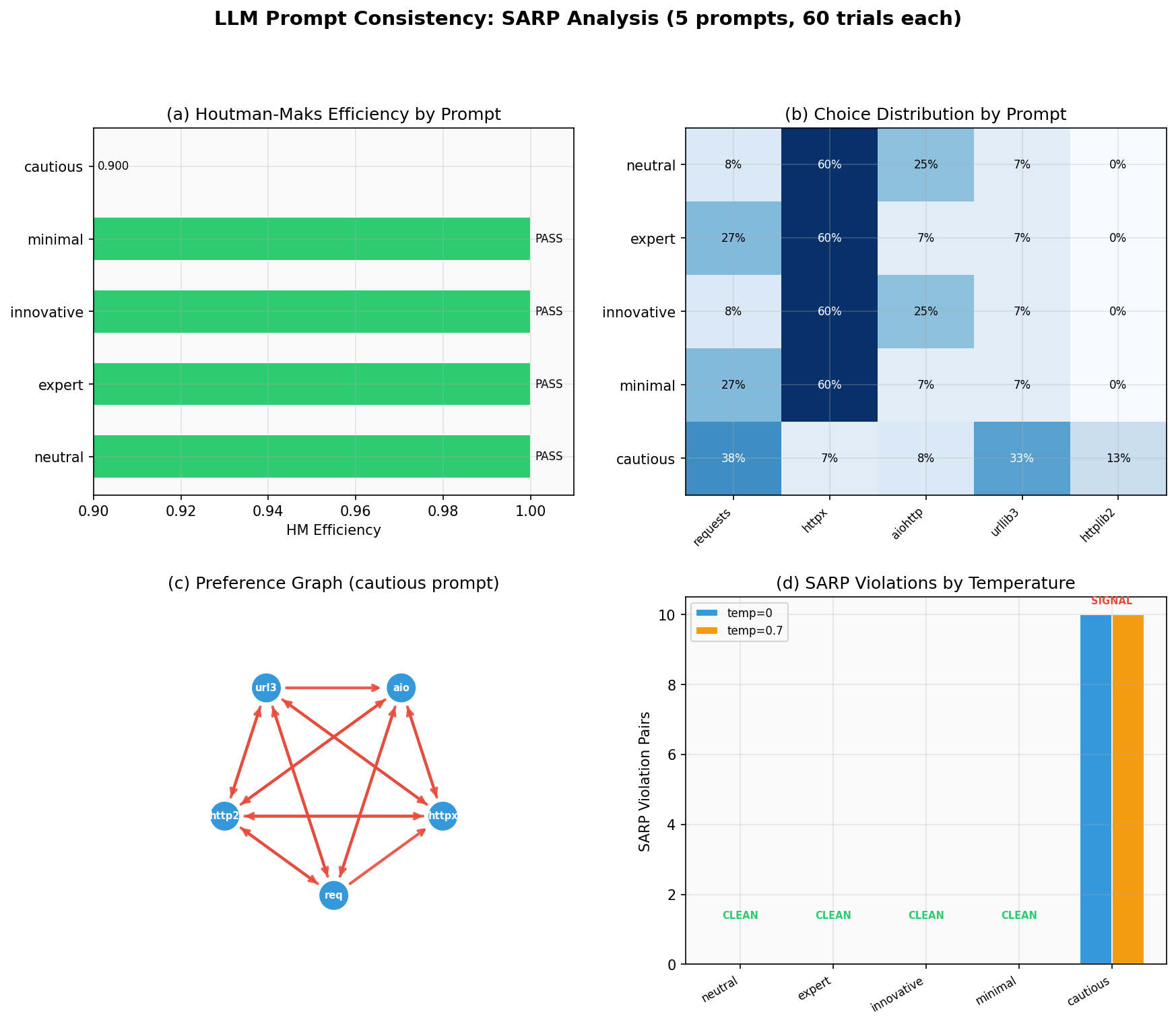
Results (GPT-4o-mini, 60 trials per prompt, March 2026):
PROMPT CONSISTENCY RANKINGS (temp=0.7)
Prompt Valid SARP Violations HM eff Top choice %
-------------- ----- ------ ---------- -------- ------------ ------
neutral 59 PASS 0 1.000 httpx 50.8%
expert 60 PASS 0 1.000 httpx 50.0%
innovative 53 PASS 0 1.000 httpx 54.7%
minimal 60 FAIL 1 0.967 httpx 50.0%
cautious 60 FAIL 1 0.950 requests 51.7%
BASELINE COMPARISON: temp=0 vs temp=0.7
neutral temp=0: 0 viol temp=0.7: 0 viol → CLEAN
expert temp=0: 0 viol temp=0.7: 0 viol → CLEAN
cautious temp=0: 1 viol temp=0.7: 1 viol → SIGNAL
innovative temp=0: 0 viol temp=0.7: 0 viol → CLEAN
minimal temp=0: 0 viol temp=0.7: 1 viol → NOISE
Interpretation
What the results show
The dual-temperature design separates genuine prompt-induced inconsistency (SIGNAL) from sampling noise (NOISE):
Cautious prompt: the only prompt with a genuine SARP violation (persists at temp=0). The stability-first framing creates a real preference conflict: the model is torn between
requests(stable) andurllib3(low-level, foundational), producing menu-dependent choices. This contradicts the prior hypothesis that cautious prompts would be most consistent.Innovative prompt: perfectly consistent despite shifting preferences entirely to
httpx(55%) andaiohttp(45%). A different ranking than the default, but an internally coherent one.Minimal prompt: one NOISE violation (temp=0.7 only). At temp=0 it has a fixed ranking; the violation is a sampling artifact.
Neutral/expert: clean at both temperatures. The default model behavior is inherently SARP-consistent.
Practical applications
Prompt selection: Before deploying an LLM agent for tool/package selection, run this experiment with candidate system prompts. Choose the prompt with highest HM efficiency.
Consistency monitoring: Run periodically across model versions. A drop in HM signals that a model update changed the agent’s implicit preference structure.
Persona risk assessment: Specialized personas (expert, innovative) may reduce consistency by introducing conflicting objectives. Quantify this trade-off before deploying.
Temperature tuning: Repeat the experiment at different temperatures. Find the highest temperature that maintains acceptable SARP consistency.
Limitations
SARP assumes deterministic choice. At temperature > 0, the LLM is a stochastic process. SARP violations may be sampling noise, not genuine preference cycles. The correct axioms for probabilistic choice are RUM consistency and regularity (Block & Marschak 1960; Kitamura & Stoye 2018), available in
prefgraph.contrib.stochastic. A temp=0 baseline is essential to separate prompt effects from sampling noise.Only tests 5 packages in one domain (HTTP libraries). Real deployments involve more items and domains.
The experiment assumes the LLM follows the “choose one” instruction. Parse failures (malformed responses) are excluded from analysis.
100 trials per prompt may be insufficient for rare menu combinations. Increase trials for production-grade audits.